It’s Time for Big Tech Companies to Devote 1% Of Their Compute Power to Social Good
By Alex Sarlin and Ben Kornell
At Edtech Insiders, we have chronicled the rise of AI in education, including new product capabilities, business models, gaps in support, and more. This week we highlight a key bottleneck that everyone is facing when it comes to AI: compute capacity.
While we have been on an exponential trajectory of total compute power over the last decade, the explosion of Generative AI and LLMs is finally catching up. Today, computing capacity constrains all AI products and services, and thus there is a race to hoard AI chips, specifically Nvidia’s GPUs, and to develop new chips like Google’s TPU.
This has significant implications for AI in edtech and AI for social impact in general, so let’s dive into the origins of this issue and how we might solve it.
Compute Power: An Essential Ingredient of AI
“Three factors drive the advance of AI: algorithmic innovation, data… and the amount of compute available for training… ... since 2012, the amount of compute used in the largest AI training runs has been increasing exponentially with a 3.4-month doubling time (by comparison, Moore’s Law had a 2-year doubling period). Since 2012, this metric has grown by more than 300,000x (a 2-year doubling period would yield only a 7x increase). Improvements in compute have been a key component of AI progress, so as long as this trend continues, it’s worth preparing for the implications of systems far outside today’s capabilities.”
In simple terms, AI development requires three main components: algorithmic innovation, massive amounts of data, and raw computing power (which computer scientists call ‘compute’). And across all three we have seen major breakthroughs:
Algorithmic Innovation: Many of the largest leaps in the field— expert systems, backpropagation, reinforcement learning, convolutional neural networks (CNN), recurrent neural networks (RNNs)-- are decades old. In fact, the first “Large Language Model” was from the 1950’s.
Data: Finding the massive quantities of data available to ‘train’ complex artificial intelligence has been THE bottleneck for generations. But that was BI (before the internet); that is, before the era when
over 400 hours of video are uploaded to YouTube every minute.
A new website is built every three seconds to complement the 200 million active ones in existence billion archived (Source)
Compute: But there is one final ingredient in all AI models. It’s the most basic one of all - raw computing power- the huge amount of hardware (that is, literally, chips) that must be used to train and operate these unbelievably complex AI models with billions of parameters.
The Hardware Powering AI: GPUs
The most powerful and ubiquitous chips used to train AI models are GPUs (Graphics Processing Units) built by California based Nvidia.
The H100 “Hopper” chip made by Nvidia
Originally, Nvidia’s GPUs were built to power graphics for video games. In 1999, they released the first GPU, the GeForce 256. The chip was capable of processing a minimum of 10 million polygons per second— polygons are the individual shapes that make up 3-D graphics— and had four 64-bit pixel ‘pipelines’ that could run in parallel, using multiple "streaming multiprocessors.”
Graphical computing performance has been (imperfectly) measured in ‘flops’ (floating point operations per second, or “calculations that involve decimal points per second”). The GeForce 256 was capable of 50 gigaflops - 50 billion flops. These days, most individual chips are measured in teraflops (one trillion flops), and AI operations are often measured in petaflops (one quadrillion flops), which are achieved by running many chips in parallel. That said, the underlying architecture of these chips also continues to evolve, so chips will talk about variations of flips like RT flops (Engadget).
GPUs have ‘streaming multiprocessors’ (SMs) that work in parallel. This parallel computing allows chips to “break complex problems into thousands or millions of separate tasks and work them out all at once” (Open Metal).
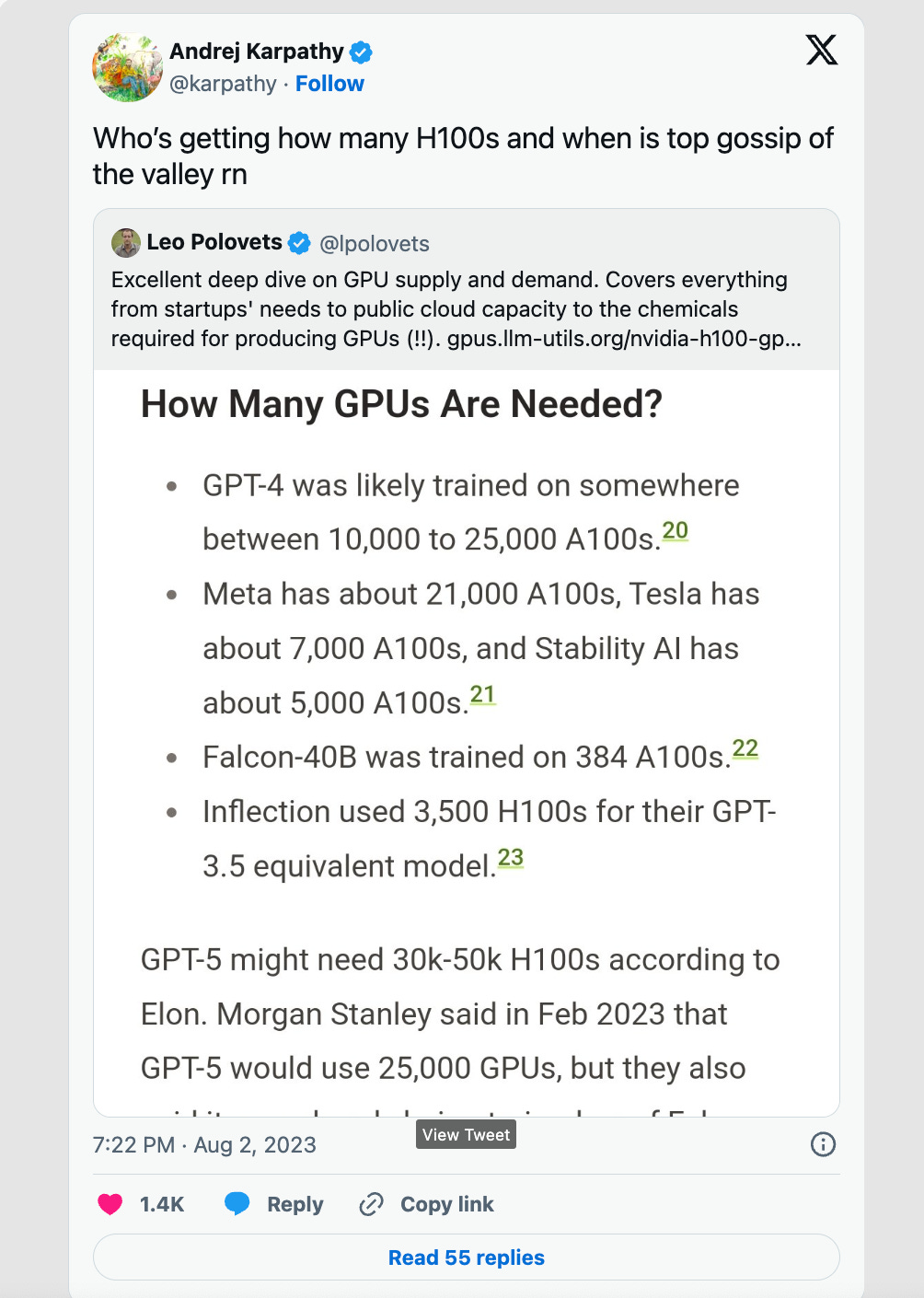
These GPUs have become the coin of the realm for AI. If AI is the ‘new electricity’, as AI pioneer Andrew Ng likes to say, then GPUs are the power grid. To train massive AI models, companies need to hoard these chips by the thousands.
Today, Nvidia owns 87% of the GPU market, to rival AMD’s 10%. It sells the most popular and powerful consumer GPUs in the world which are mostly used for gaming:
The GeForce RTX™ 3060 VENTUS (12.74 Teraflops, retails for $289.99)
The GeForce RTX 4090 (191 RT-Teraflops, $1,599)
The Titan V (110 teraflops, $2,999).
For data centers that exclusively train AI models, their most powerful chips take center stage:
The A100 (312 Teraflops, $10,000)
The H100 chip (500 FP16 Teraflops, $40,000)
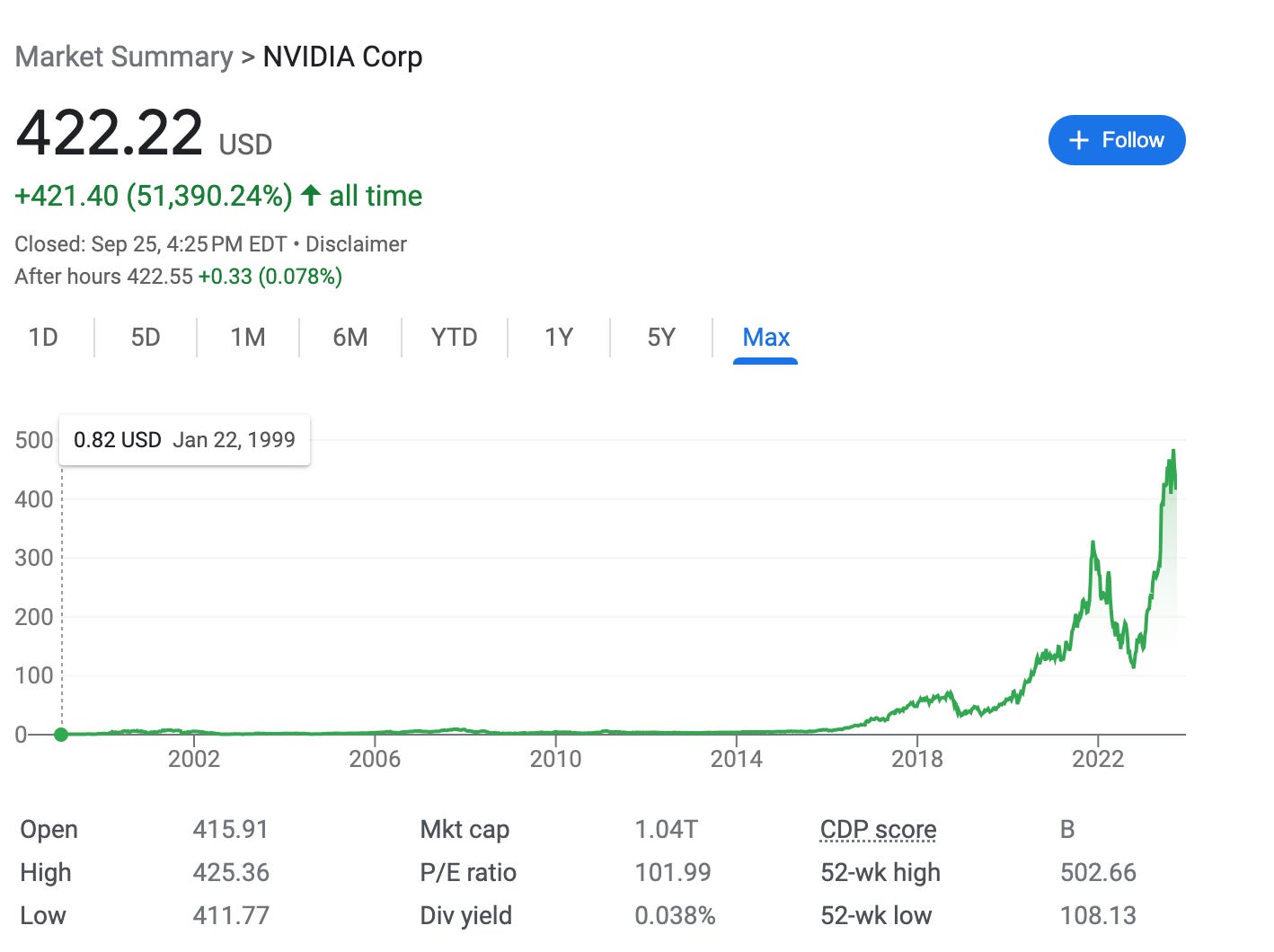
Because of the need and demand for GPUs right now, manufacturers are able to sell chips at extremely high prices, and like any physical commodity, the amount available is limited. This has created a host of access problems in AI as a field, with highly funded companies hoarding technology that is needed to do anything with AI. Manufacturers are reaping the benefits through increased revenue and stock prices (see NVIDIA’s 20-year trend below), but also in their leverage to strike equity deals with companies.
NVIDIA stock at $422 per share
Why this is particularly problematic for education
Any teacher will attest to the minimum bar for all edtech - ‘it has to work.’ Time-constrained educators demand reliability, speed, and accuracy from edtech tools as they navigate high stress classrooms. Students need just-in-time solutions that deliver ahead of exams, problem sets, and projects. For products predicated on LLM queries, the AI compute constraints are creating real barriers in meeting education users’ fundamental needs.
There are a variety of ways this plays out. Most edtech platforms now experience some form of rate-limiting - this means that an LLM restricts the number of queries for a given time period for a particular model. For example, In August, the average rate limit for GPT-4 corporate users is 10,000 TPM (tokens per minute) and 200 RPM (requests per minute), while consumers using ChatGPT Plus had a limit of 25 messages every 3 hours. Query latency and reduced performance during high-demand periods has also been a challenge, particularly for OpenAI customers. While the challenge is with the underlying LLM, customers experience this as ‘the product is down’ or too slow.
The work-arounds often lead entrepreneurs to batch prompts / queries, downgrade from GPT 4 to 3.5, or build in back-up open source LLMs when rate-limits are reached or latency is high. In some rare cases, companies are turning to universities or the government for additional compute capacity.
But these work-arounds don’t address the longer-term problem: as compute demand grows, supply is not keeping up, and this inevitably drives prices up and access down. AI in education can’t compete with the ability / willingness to pay from large tech companies and trillion-dollar industries.
What Now: Prioritizing Equity and Access in AI
The big hope is that innovations in chip design and manufacturing will ultimately solve this constraint in the long-run. If history is any indicator, the unchecked demand for GPUs will inevitably drive more supply and also chip innovation. That said, our current demand curve is pointing vertically, while chip supply is constrained by real physical production capacity. So at least for the medium term, available compute will be the lid on what’s possible and practical for AI in every field, including education.
At EdTech Insiders, we think this is a bold moment for tech companies, particularly NVIDIA and Google, to commit a portion of their compute capacity - starting at 1% - to fuel AI for non-governmental social impact organizations. For NVIDIA, 1% would be between $145M-$326M/year in compute value with the potential to grow to as much as $1B annually by 2026. Dedicated compute would be an important step in the direction of equitable access to AI, and it would establish the direct connection between tech company compute power and the public interest.
To manage this compute commitment, we would imagine an independent “AI Compute Trust” that could acquire GPU chips directly and also reserve dedicated processing capacity from the major LLMs. The trust would be able to trade credits depending on demand so that any unused capacity from social impact organizations could be banked for future compute. The Trust would have to develop a transparent qualification process to distribute reliable and low-cost compute capacity across fields like education, healthcare, and social services.
Non-profits with specific AI-for-impact products would qualify for compute grants, just as they would get financial grants from philanthropy. Qualifying for-profit social impact organizations could access AI Compute Trust capacity for R&D and early stage development and over time graduate to partial or full-use of market-rate AI compute power. In edtech, Trust allocations would fundamentally change AI economic models and accelerate the ability for new AI tools to serve low-income schools, families and communities.
This is just one idea that much smarter folks can build upon, but it goes to a core fact: access to compute will help to define the winners and losers in this new Age of AI. Let’s make sure ALL kids are on the winning side by reserving some of that compute for them!
The AI + EDU Virtual Conference
In our last newsletter, we announced that we are hosting the The AI + EDU Conference, and since then 135 members of our community have already bought tickets to attend! Wow!
We are so excited to see you all there, and want to encourage you to get your tickets now if you’re planning to join us! We already have an INCREDIBLE list of 35 speakers who will be joining us for the day (you can see the full list of speakers here) and even more speakers that we’ll be announcing soon!
Here’s a sneak preview of some of the panel discussion we’ll be hosting… be sure to check out our event page for in depth descriptions for each of these panel discussions and to see who is speaking on each topic!
Our currently announced panel discussions include:
America's Next Top Model: LLMs in Educational Settings
Hello, Mr. Chips: AI Teaching Assistants, Tutors, Coaches and Characters
A Road Less Traveled: AI-Powered Personalized Learning Paths and Study Tools
2040 Vision: Forecasting AI's Transformative Role in Education
Investing in Educational AI: Edtech Investor Panel
Machine Learning, Human Teaching: Bridging the Gap with AI-Generated Content
The Age of Superteachers: AI Tools for Augmenting Educator Impact
Skillset of the Future: A Guide to Teaching AI Skills
And more!
We are so excited to share more about the conference as we get closer to October 26! If you love what we do at Edtech Insiders, the best way you can support us is by attending and sharing in this experience of learning from and with each other!
Are you going to be in NYC for Edtech Week? If so, we’d love to see you at Magic’s Annual Rooftop Party on October 3rd in New York City! Come join us for edtech networking, some great food and drinks, and a beautiful rooftop view!
We’d love to see you there, please RSVP if you plan to attend!
Our next Bay Area Edtech Happy Hour is coming up on October 11th in San Francisco at the Common Sense Media Headquarters! This is a monthly recurring event where we come together as a community to connect, collaborate, and enjoy a drink together! Anyone is welcome to attend.
We’d love to see you there, please RSVP if you plan to attend!
As Google begins to slowly share more and more about Gemini, the soon to be released AI model that is predicted to be in competition with ChatGPT, we are on the edge of our seats to see how this will impact the education sector.
The beginning of this year was oversaturated with the launch of so many AI models that the education sector couldn’t keep up, and we expect that Gemini will be another model that will drastically shift how education is approaching and incorporating AI.
2. GenAI Surveillance Gone Wrong
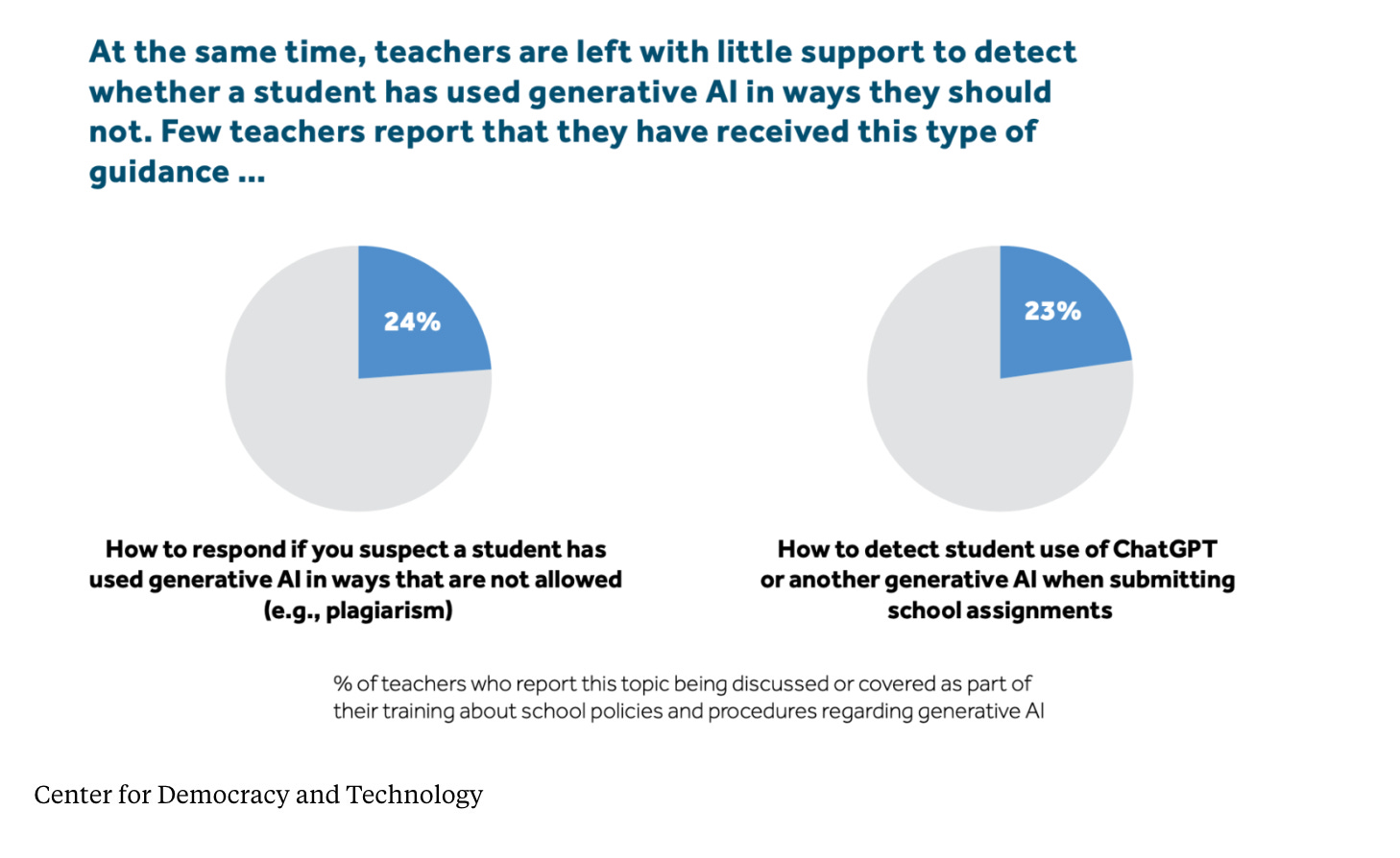
As GenAI is taking up so much space in the news, The 74 reports that K12 teachers are suspicious of their students and that students are facing consequences at school for using or being suspected of using GenAI for cheating on assignments.
29% of students reported using GenAI to deal with anxiety or mental health issues
22% of students reported using GenAI for issues with friends
16% reported using GenAI for family conflicts
This survey points to a larger problem: teachers are being left to manage and approach the growing problem of regulating GenAI in the classroom completely alone. If teachers are supportive of GenAI in the classroom, how are they supposed to be able to regulate appropriate or inappropriate uses for this technology, and then act accordingly in response?
Similarly in the Higher Ed sector, students at Harvard report that one of the major challenges they are facing is that GenAI regulation, policy, and skills are being left up to the teacher, creating a continually more difficult relationship between professors and students around this topic which bleeds into every area of the classroom.
Teachers know that students are using GenAI. However, there is still a huge opportunity to broach and support the effective regulation and integration of this technology, and until it is addressed both students and teachers will be paying the price.
3. Upskilling in GenAI
As GenAI becomes more accepted, experts are beginning to transition into predicting to what extent and how quickly individuals will need to learn GenAI skills to stay relevant in today’s workplace.
In a recent interview with Fortune Education, Founder and CEO of edX Anant Agarwal shares his belief that everyone will need to learn AI in order to continue at their jobs. Alongside this, the World Economic Forum predicts that half of the global work force may need to reskill or upskill by 2025 to accommodate for recent technological changes like GenAI.
edX recently released a white paper “Navigating the Workplace in the Age of AI” covering this exact topic of AI and re-skilling. Among many takeaways, their report shows us that AI skills are needed, wanted, and also currently under supported.
What does it look like to ensure workers are equipped with the AI education opportunities they need to stay up to date with a host of new technologies that are become the norm for today’s employees?
We’re looking forward to edtech solutions continuing to step in and respond to this need.
This edition of the Edtech Insiders Newsletter is sponsored byTuck Advisors.
Tuck Advisors is a trusted name in education M&A. Founded by serial entrepreneurs with over 25 years of experience starting, investing in, and selling companies, we believe founders deserve M&A advisors who work as hard as they do. If you receive any UFO's™, unsolicited flattering offers, be sure to reach out to us at confidential@tuckadvisors.com. We can help you determine if it's a hoax or if it's real.
We have had SO MANY amazing guests on The Edtech Insiders Podcast in the last two weeks. Make sure to check out our recent episodes, including:
Jessica Tenuta, Chief Product Officer and Co-Founder of Packback on leveraging AI to support students with writing and discussion.
James Grant, Co-Founder of MyTutor on making life-changing tutoring available to all.
Bodo Hoenen, Founder ofDev4X and a Co-Founder of NOLEJ on generative AI in education.
John Failla, CEO and Co-Founder of Pearl on how to improve tutoring in order to provide a truly customized and supportive learning experience.
Kimberly Nix Berens, Ph.D., Scientist-Educator, Founder of Fit Learning, and Author of Blind Spots on leveraging science to more effectively teach students.
Funding, Mergers, and Acquisitions
Our latest reporting on funding, mergers, and acquisitions comes from Matt Tower’s publication Edtech Thoughts. Matt does an incredible job of covering the latest funding, news, industry updates, and more! If you love Edtech Insiders, be sure to subscribe to Matt’s newsletter as well.
ELSA raises $23M / US, Language Learning / UOB Venture Management, UniPresident, Aozora Bank, Vietnam Investments Group, Development Bank of Japan, Gradient Ventures, Monk’s Hill Ventures, Global ventures